
Centrummaten en spreidingsmaten
[Terug naar overzicht hoofdstuk] [Oefening 1] [Oefening 2] [Oefening 3 (dotplot)]
Centrummaten: gemiddelde en mediaan
Om goed te begrijpen hoe de centrum-en spreidingsmaten van gegevens bepaald worden, vertrekken we telkens vanuit het volgende voorbeeld:
We bekijken de punten van 27 leerlingen. Deze leerlingen hebben een toets afgelegd op 10 punten. Onderstaande waarnemingstabel stelt hun punten voor:

Gemiddelde
Om het gemiddelde van alle punten te bepalen, kunnen we de som maken van alle punten en vervolgens delen door het aantal leerlingen.
We stellen nu een frequentietabel op van alle punten (eventueel door het trekken van streepjes, ook wel ‘turven genoemd’)
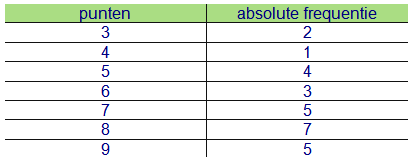
Om het gemiddelde te berekenen, kunnen we de verschillende waarnemingsgetallen vermenigvuldigen met de bijhorende frequenties en deze producten optellen. Deze som wordt dan uiteindelijk gedeeld door het aantal data.
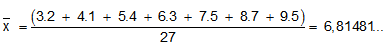
Merk op: Als in een reeks data enkele zeer grote of zeer kleine data voorkomen, wordt het gemiddelde sterk beïnvloed door deze data. Aangezien we in dat geval een vertekend beeld krijgen, is het gemiddelde hier geen goede centrummaat!
Mediaan (Med)
We werken opnieuw met de behaalde punten in de klas en rangschikken deze nu van klein naar groot:

Aangezien er 27 leerlingen zijn, is het veertiende getal (een zeven) het middelste getal in deze tabel. Dit getal wordt de mediaan genoemd van de reeks data en wordt genoteerd als ‘Med’.
Med = 7
Indien het aantal data een even getal is, nemen we de twee middelste puntenwaarden en delen het vervolgens door twee. Hieronder volgt een voorbeeld:


Merk op: Voor een reeks data waarin sommige data sterk afwijken van de andere data, is de mediaan een geschikte centrummaat! Omdat we hier een even aantal data hebben (namelijk 10), vinden we de mediaan door de som te maken van het vijfde en zesde getal én vervolgens te delen door 2. De mediaan van bovenstaande reeks is bijgevolg gelijk aan , ook al komt het getal 4 zelf niet voor in de reeks data.
Spreidingsmaten: spreidingsbreedte (variatiebreedte),interkwartielafstand, variantie en standaarddeviatie (standaardafwijking)
Spreidingsbreedte of variatiebreedte
We vertrekken vanuit de reeds gerangschikte data. De punten van de leerlingen worden dus weergegeven van klein naar groot:

Het verschil tussen het grootste en kleinste waarnemingsgetal noemen we de spreidingsbreedte of variatiebreedte van de gegeven reeks (notatie: xmax - xmin ). In dit voorbeeld is de spreidingsbreedte dus gelijk aan 9 - 3 = 6.
Interkwartielafstand
We beschouwen opnieuw de reeks voorgaande punten. De mediaan 7 (aangeduid in het geel) verdeelt de reeks op zijn beurt in twee helften. Als we de mediaan van de linkerhelft en deze van de rechterhelft bepalen, verdelen de drie medianen de reeks punten in vier gelijke delen of kwarten.

Links van de mediaan 7 bevinden zich nog 13 getallen. Dit betekent dat het zevende getal (een 5) in de helft ligt. We noemen dit getal 5 het eerste kwartiel omdat het eerste kwart van de punten links van dit getal ligt.
We noteren: Q1 = 5
De mediaan 8 van de rechterhelft noemen we het derde kwartiel omdat het derde kwart van de punten links van dit getal ligt
We noteren: Q3 = 8
Het verschil Q3 - Q1 noemen we interkwartielafstand van de gegeven reeks punten. We noteren: Q3 - Q1 = 8 - 5 = 3
Variantie en standaarddeviatie
Om een idee te krijgen van hoe de data gespreid liggen rond het gemiddelde, berekenen we de verschillen van alle behaalde punten t.o.v. dat gemiddelde.
Een leerling die een 8 behaalde, heeft 1,2 punten meer dan het gemiddelde van 6,8. (8–x = 1,2). Voor een leerling die slechts een drie scoorde, is het puntenaantal 3,8 lager dan het gemiddelde (3–x = –3,8)
Om de afwijkingen t.o.v. het gemiddelde te benadrukken én positief te maken, kunnen we de verschillen kwadrateren! Zo is de gekwadrateerde afwijking van 3 tot 6,8 gelijk aan (–3,8)² = 14,44. De gekwadrateerde afwijking van 6,8 tot 8 is gelijk aan (1,2)² = 1,44
Als we de verschillen tussen alle data en het niet-afgeronde gemiddelde kwadrateren, optellen en de bekomen som delen door het aantal data, vinden we (werkend met de niet gerangschikte gegevens):
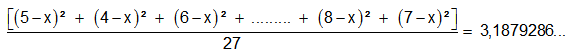
Het bekomen getal wordt de variantie s² van de puntenreeks genoemd. De positieve vierkantswortel van de variantie, wordt de standaardafwijking of standaarddeviatie genoemd en wordt voorgesteld met een kleine letter sigma.
De standaarddeviatie van een reeks data wordt meestal met 1 of 2 decimalen meer genoteerd dan de gegeven data!
We noteren: s = 1,8 (dit is de afgeronde vierkantswortel van de variantie 3,1879286...)
Definitie: De standaarddeviatie is de positieve vierkantswortel van de variantie die het gemiddelde is van de gekwadrateerde afwijkingen t.o.v. het gemiddelde van een reeks data
Om de centrum-en spreidingsmaten visueel voor te stellen, maken we gebruik van een boxplot. Stel dat we de punten van een toets op 11 punten visueel voorstellen met een boxplot:
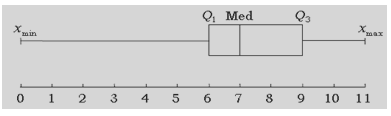
We kunnen afleiden dat 25% van de leerlingen minder haalde dan 6/10, aangezien Q1 gelijk is aan 6.
Zo kunnen we ook afleiden dat 25% van de leerlingen meer haalde dan een 9.